
1. matplotlib library
: Python 프로그래밍 언어 및 numpy 라이브러리 Data를 선, 막대, 산점도, 히스토그램, 파이, 박스, 바이올 등으로 시각화해주는 그래픽 라이브러리입니다. png, pdf, svg 등의 포맷으로 저장이 가능합니다.
2. plot 그리기
: matplotlib.pyplot을 plt로 불러와서 아래 code를 입력하면 아래와 같은 그래프를 얻을 수 있습니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(5,2))
plt.plot([1,2,3,4,5],[1,4,6,9,25], 'go')
plt.show()
| plt.figure(figsize=(가로 인치, 세로 인치)) | 그래프 size 결정 |
| plt.plot([ x좌표 ],[ y 좌표]) | 그래프의 x, y 좌표 설정 |
| plt.show() | : 그래프를 그리는 명령어 |

: 이번에는 그래프 스타일(ggplot) 및 마커(circle)에 변경을 주겠습니다. 다른 설정에 대한 option은 link에서 확인이 가능합니다.
plt.style.use('ggplot')
plt.plot([1,2,3,4,5], [1,4,6,9,25], 'go')
plt.show()
| plt.style.use('ggplot') | 그래프의 형식을 지정 |
| plt.plot([1,2,3,4,5], [1,4,6,9,25], 'go') | 'go'는 green circle 을 의미 |

: 그래프의 제목 및 x, y 축 이름을 지정해보겠습니다.
plt.figure(figsize=(3,3))
plt.plot([1,2,3,4,5],[1,4,6,9,25], 'go:')
plt.title("Graph")
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
| plt.plot([1,2,3,4,5],[1,4,6,9,25], 'go:') | go: 은 green + circle + dotted line style 를 의미 |
| plt.title("Graph") | 그래프 이름을 Graph로 설정 |
| plt.xlabel('X') | x축 이름을 X로 설정 |
| plt.ylabel('Y') | y축 이름을 Y로 설정 |

: 이번에는 한번에 여러개의 선을 그리는 방법을 확인해 보겠습니다.
x_label = ['Jan','Feb','Mar','Apr','May','Jun']
y_label_01 = [100,60,70,80,65,90]
y_label_02 = [50,80,30,10,90,60]
y_label_03 = [80,70,60,75,45,80]
plt.plot(x_label, y_label_01, 'ro-', label="y_label_01")
plt.plot(x_label, y_label_02, 'bo--', label="y_label_02")
plt.plot(x_label, y_label_03, 'go:', label="y_label_03")
plt.legend(loc='lower right')
plt.xlim(-0.5,5.5)
plt.ylim(0,105)
plt.show()
| plt.plot(x_label, y_label_01, 'ro-', label="y_label_01") | label의 이름을 y_lable_01로 지 |
| plt.legend(loc='lower right') | label 을 표시하는 위치를 low right 로 지정 |
| plt.xlim(-0.5,5.5) | x축 범위 |
| plt.ylim(0,105) | y축 범위 |

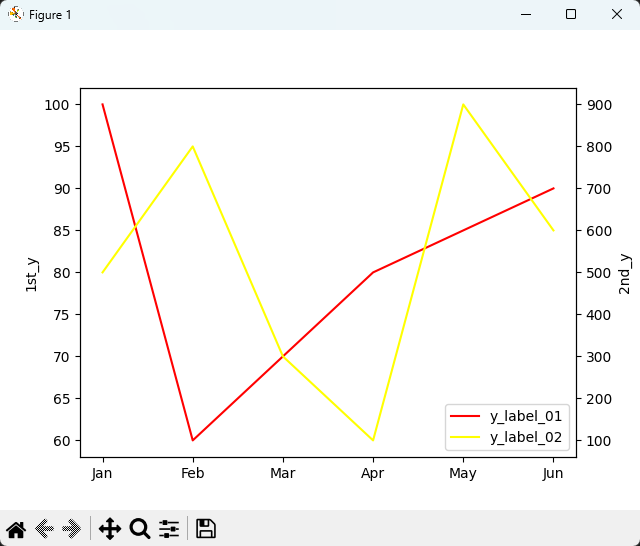
: 이중 y축을 사용한 꺾은선 그래프이다. 하나의 그림위에 axis를 두개 생성해서 각 axis에 그래프를 그린 뒤 합친다고 생각하면 된다.
fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
x_label = ['Jan','Feb','Mar','Apr','May','Jun']
y_label_01 = [100,60,70,80,85,90]
y_label_02 = [500,800,300,100,900,600]
line_01 = ax1.plot(x_label, y_label_01, color = "red", label="y_label_01")
line_02 = ax2.plot(x_label, y_label_02, color = "yellow", label="y_label_02")
lines = line_01 + line_02
ax1.set_ylabel("1st_y")
ax2.set_ylabel("2nd_y")
labels = [line_01[0].get_label(), line_02[0].get_label()]
plt.legend(lines, labels, loc="lower right")
plt.show()
'데이터 처리' 카테고리의 다른 글
| 1. pandas 기초 (0) | 2024.07.20 |
|---|
